Im2Pano3D:
Extrapolating 360° Structure and Semantics Beyond the Field of View
Abstract
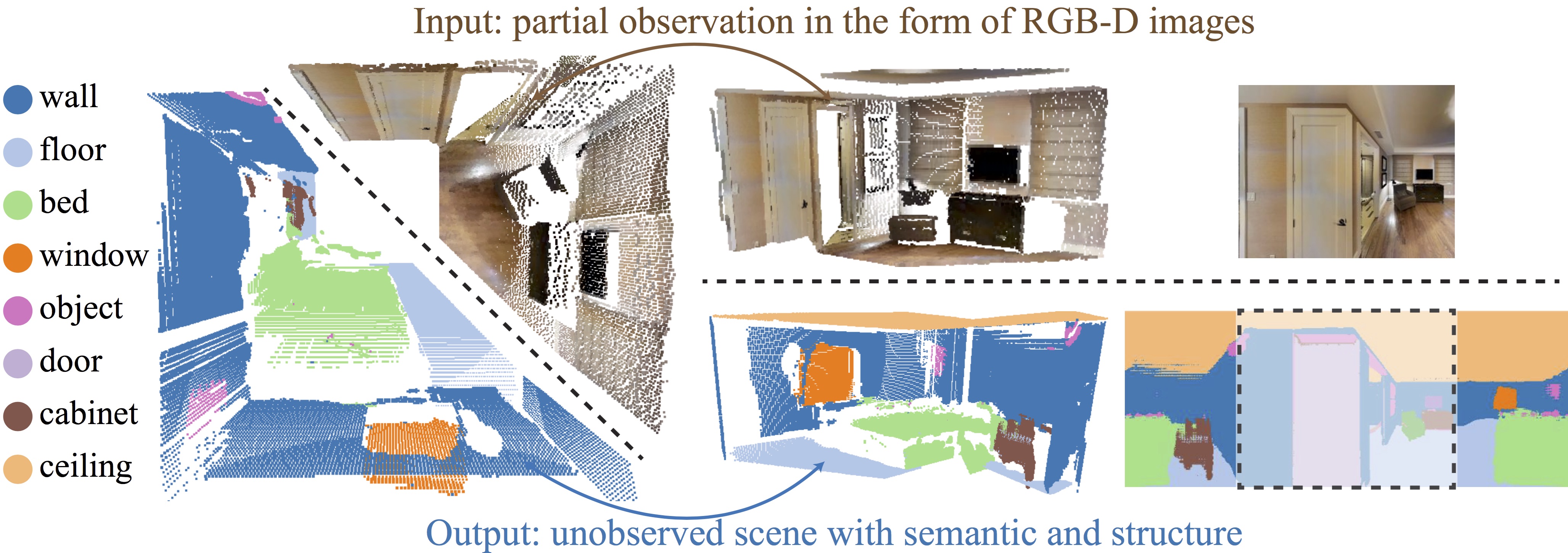
We present Im2Pano3D, a convolutional neural network that generates a dense prediction of 3D structure and a probability distribution of semantic labels for a full 360° panoramic view of an indoor scene when given only a partial observation (<= 50%) in the form of an RGB-D image. To make this possible, Im2Pano3D leverages strong contextual priors learned from large-scale synthetic and realworld indoor scenes. To ease the prediction of 3D structure, we propose to parameterize 3D surfaces with their plane equations and train the model to predict these parameters directly. To provide meaningful training supervision, we use multiple loss functions that consider both pixel level accuracy and global context consistency. Experiments demonstrate that Im2Pano3D is able to predict the semantics and 3D structure of the unobserved scene with more than 56% pixel accuracy and less than 0.52m average distance error, which is significantly better than alternative approaches.
Paper
-
Shuran Song, Andy Zeng, Angel X. Chang, Manolis Savva, Silvio Savarese, Thomas Funkhouser
Im2Pano3D: Extrapolating 360° Structure and Semantics Beyond the Field of View ( arXiv, Dec 2017 )
[paper] [bibtex] [code] [talk(.key)] [talk(.pdf)] [poster(.pdf)]
Video
RGB-D Panorama Dataset
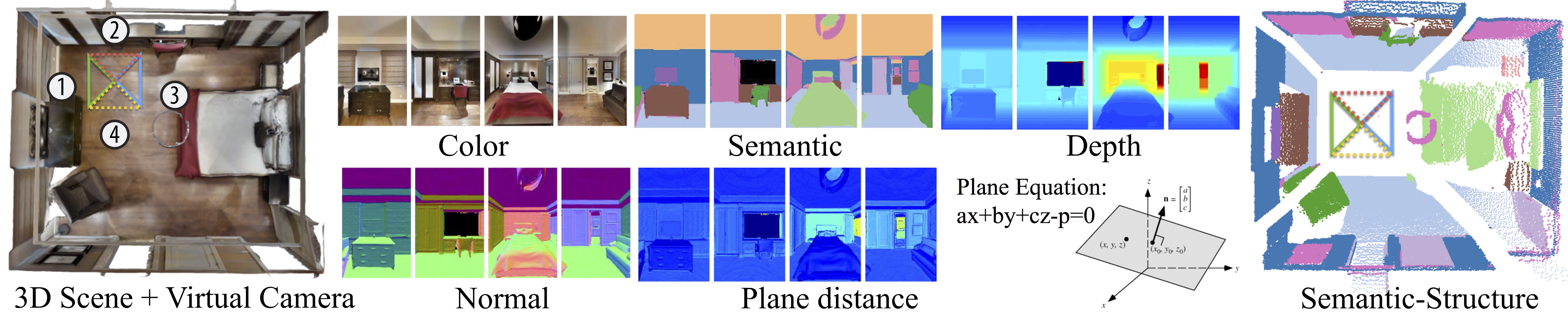
- We generate RGB-D Panorama imaes from SUNCG dataset and Matterport dataset.
- Each panorama has color image, semantic segmentation, depth, and it's plane encoding (plane distance and surface normal).
- You can download the data for [Matterport] and [SUNCG]. and example codes to read and visulize the data [code].
Camera Configrations
Here we demonstrate how Im2Pano3D can generalize to different camera configurations. The camera configurations we consider includes: single or multiple registered RGB-D cameras such as Matterport cameras (a-d), single RGB- D camera capturing a short video sequence (e), color-only panoramic camera (f), and color panoramic cameras paired with a single depth camera (g). To improve the ability of the network to generalize to different input observation pat- terns, we use a random view mask during training. Tab.3 shows the qualitative evaluation. For all of these camera configurations, Im2Pano3D provides a unified framework that effectively fills in the missing 3D structure and semantic information of the unobserved scene.
Example Results


